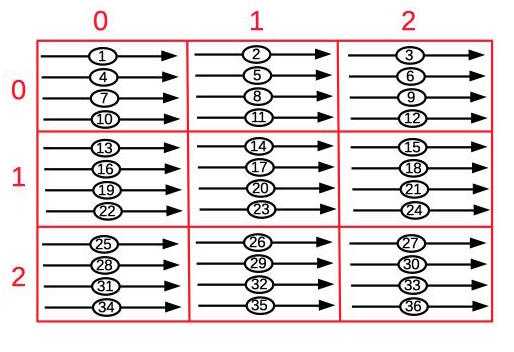
Storing 2-D data in a row-major 1-D array
You may find the use of a 1-D array to store the pixels surprising, since after all the image is 2-D. However, it is
common to use 1-D arrays, especially when they are dynamically allocated. One option would be to allocate an array
of pointers to
1-D arrays, where each 1-D array represents a pixel row. This would make it possible to access elements with the convenient syntax Array[i][j].
But this is typically a bad idea as it reduces locality (i.e., the efficient use of the cache), which in turns harms
performance.
Therefore, we instead store 2-D data into a 1-D array of contiguous elements. The "row-major" scheme consists in storing rows in sequence. In other
terms, if the width of the image is N, then pixel (i,j) is stored as Array[i * N + j]. This is actually
the scheme used by the C language to store 2-D arrays.